Switch Transformers by Google Brain Projesi, Yapay Zeka Örnekleri

 0
0
Switch Transformers by Google Brain










 Switch Transformers by Google Brain Hakkında
Switch Transformers by Google Brain Hakkında
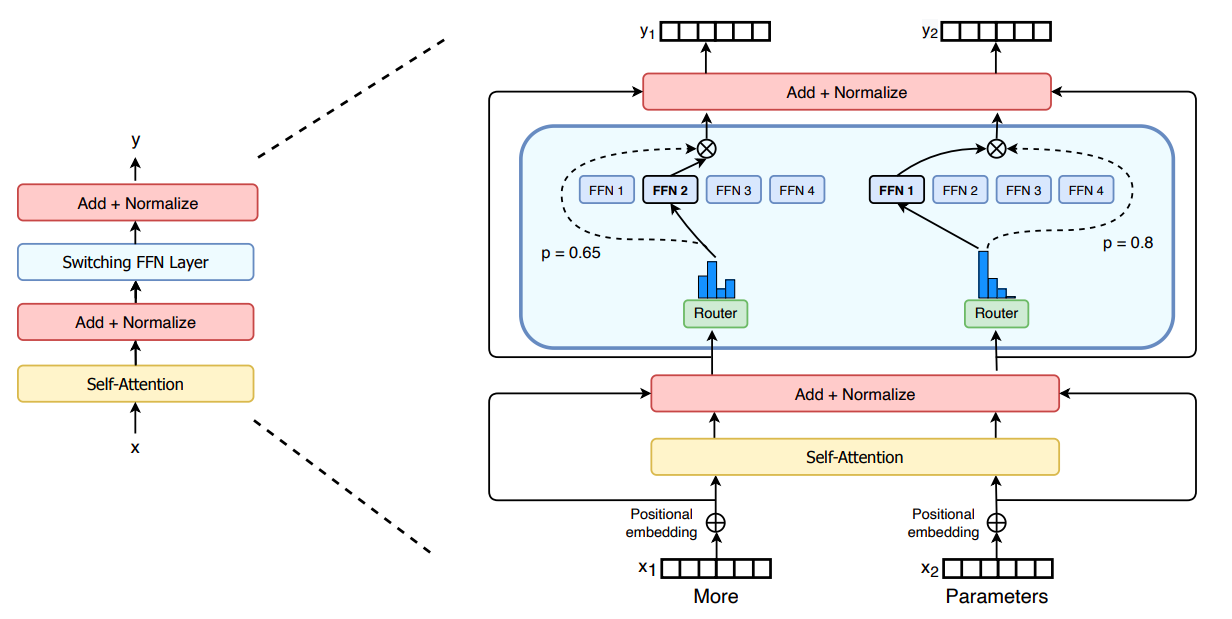
Derin öğrenmede, modeller tipik olarak tüm girdiler için aynı parametreleri yeniden kullanır. Uzman Karışımı (MoE) buna meydan okur ve bunun yerine gelen her örnek için farklı parametreler seçer. Sonuç, aşırı sayıda parametreye sahip, ancak sabit bir hesaplama maliyetine sahip, seyrek olarak etkinleştirilen bir modeldir. Bununla birlikte, MoE'nin birkaç dikkate değer başarısına rağmen, karmaşıklık, iletişim maliyetleri ve eğitim istikrarsızlığı yaygın benimsemeyi engelliyor – bunları Switch Transformer ile ele alıyoruz. MoE yönlendirme algoritmasını basitleştiriyoruz ve azaltılmış iletişim ve hesaplama maliyetleriyle sezgisel olarak geliştirilmiş modeller tasarlıyoruz. Önerdiğimiz eğitim teknikleri istikrarsızlıkların giderilmesine yardımcı oluyor ve büyük seyrek modellerin ilk kez daha düşük hassasiyetli (bfloat16) formatlarla eğitilebileceğini gösteriyoruz. Aynı hesaplama kaynaklarıyla eğitim öncesi hızda 7 kata kadar artış elde etmek için T5-Base ve T5-Large tabanlı modeller tasarlıyoruz. Bu iyileştirmeler, 101 dilin tamamında mT5-Base sürümüne göre kazanımları ölçtüğümüz çok dilli ayarlara kadar uzanır. Son olarak, "Colossal Clean Crawled Corpus" üzerinde trilyon parametre modeline kadar ön eğitim vererek dil modellerinin mevcut ölçeğini ilerletiyoruz ve T5-XXL modeline göre 4 kat hızlanma elde ediyoruz.
Makalenin tamamını https://arxiv.org/abs/2101.03961 adresinde okuyun.